2024-10-140
pandas 字符串转int64
py# 1. 将 bid 列中无效的值(如空字符串、None)替换为 NaN
df['bid'] = df['bid'].replace([None, ''], np.nan)
# 2. 使用 pd.to_numeric 将字符串转换为数值,并处理无法转换的情况
df['bid'] = pd.to_numeric(df['bid'], errors='coerce')
# 3. 将 NaN 值(空值)填充为 0 或者你想要的默认值
df['bid'] = df['bid'].fillna(0)..astype('uint64', errors='ignore')
2024-09-260
shell学习
shell基础
- 环境变量可以从父shell传给子shell,即当子Shell产生时,它会继承父Shell的环境变量为自己所用
- declare -a Name=("john" "sue") 报错zsh: unknown file attribute: j
- 原因是使用的是zsh, 而declare是bash的命令
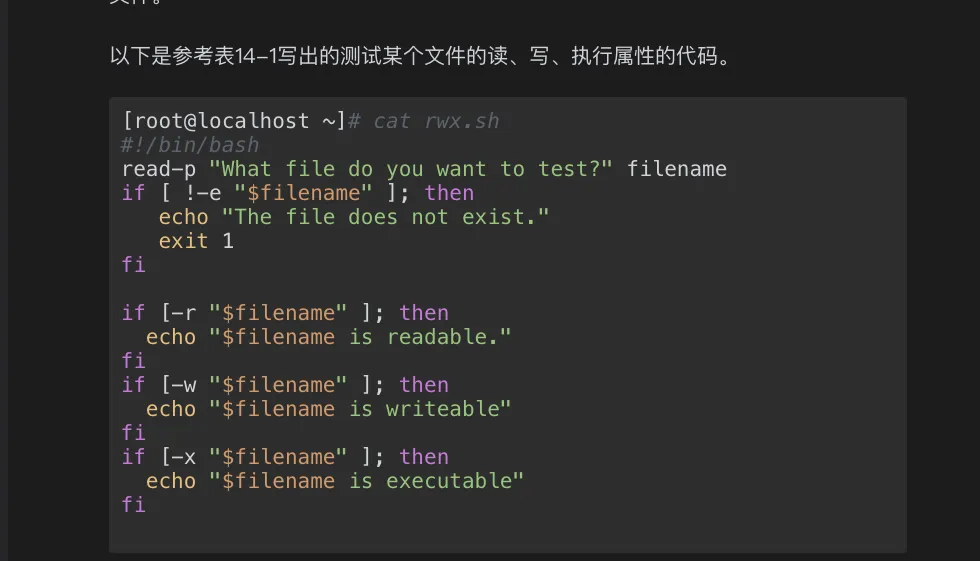
- 测试某文件的读写执行属性的代码
2024-08-090
学习背景
很多linux相关的知识都不太了解,所以需要不断地补充自己的知识储备
单机架构的三大问题
- 数据量上限
- 磁盘、内存、CPU 都有限
- 性能瓶颈
- 查询再快,也只能一台机器扛
- 单点故障
- 机器一挂,服务直接不可用
单机扛不住,所以需要分布式
ss 命令的使用(linux 专有命令)
-
概念: socket statistics的缩写
-
作用
- TCP/UDP
- 端口监听
- 网络连接
- 进程占用
-
常用命令
ss -lntp | grep nginx参数 含义 -l listening,仅查看监听 -n 数字显示端口 -t TCP -p 显示进程 -a 查看所有 socket
排查内存使用情况
ps
shps aux --sort=-%mem |head
top- Shift + M 键(注意大写),按照内存使用量排序进程。
- Shift + P 键(注意大写),按照cpu使用量排序进程。
查看服务状态
jssystemctl status nginx.service -l
核实服务端口
js ps -ef | grep nginx
root 14230 14210 0 09:07 ? 00:00:00 nginx: master process nginx -g daemon off;
101 14445 14230 0 09:07 ? 00:00:00 nginx: worker process
101 14446 14230 0 09:07 ? 00:00:00 nginx: worker process
root 18205 11594 0 09:15 pts/0 00:00:00 grep --color=auto nginx
[root@localhost nginx_update_docker]# ss -lntp | grep nginx
LISTEN 0 511 *:4430 *:* users:(("nginx",pid=14446,fd=9),("nginx",pid=14445,fd=9),("nginx",pid=14230,fd=9))
LISTEN 0 511 *:4430 *:* users:(("nginx",pid=14446,fd=7),("nginx",pid=14445,fd=7),("nginx",pid=14230,fd=7))
LISTEN 0 511 127.0.0.1:80 *:* users:(("nginx",pid=14446,fd=8),("nginx",pid=14445,fd=8),("nginx",pid=14230,fd=8))
LISTEN 0 511 127.0.0.1:80 *:* users:(("nginx",pid=14446,fd=6),("nginx",pid=14445,fd=6),("nginx",pid=14230,fd=6))
[root@localhost nginx_update_docker]# ps -o pid,ppid,cmd -p 14230,14445,14446
PID PPID CMD
14230 14210 nginx: master process nginx -g daemon off;
14445 14230 nginx: worker process
14446 14230 nginx: worker proces
gcc
GCC 是一个工具链,用于编译代码,将代码与各种库依赖项连接,并为程序集,最后形成可执行文件。GCC 遵循标准的 UNIX 设计理念,工具简单,但效果和性能一流。GCC 开发组件利用多个分散的工具辅助软件编译。
yum
shyum的全称为Yellow dog Updater,Modified,是一个基于RPM的shell前端包管理器,能够从指定的服务器上(一个或多个)自动下载并安装或更新软件、删除软件。其最大的好处是可以自动解决依赖关系。RedHat和CentOS的版本为5以上的都会默认安装yum,所以该命令可以直接使用。
2024-08-060
linux查看内存占用命令
shps aux --sort=-%mem |head
或者top 然后按下 Shift + M 键(注意大写),按照内存使用量排序进程。
shtop
2024-08-020
背景:有时候需要校验文件内容是否拉取完成,可以通过md5加密进行判断
通过python的加密实现
pythondef cal_file_md5(file_path):
'''
计算渠道包(未签名)md5
:param file_path:
:return:
'''
try:
# with open(file_path, 'rb') as fp:
# data = fp.read()
# file_md5 = hashlib.md5(data).hexdigest()
# return file_md5
m = hashlib.md5()
with open(file_path, 'rb') as fp:
while True:
# 分块读取,一次20M(20*1024*1024)
data = fp.read(20971520)
if not data:
break
m.update(data)
file_md5 = m.hexdigest()
return file_md5
except Exception as e:
r_logger.loginfo('[渠道包md5计算错误]:' + file_path + str(e))
r_alert.alert_admin('[渠道包md5计算错误]:' + file_path + str(e))
return False
2024-07-310
2024-07-290
Python的线程更适合处理I/O密集型任务(如网络请求、文件读写),因为GIL不会阻碍I/O操作的并发。
pythonimport threading
# 定义要在每个线程中执行的任务
def worker(thread_id):
print(f"线程 {thread_id} 正在执行任务")
# 在这里添加实际的任务代码
# 模拟任务执行时间
import time
time.sleep(1)
print(f"线程 {thread_id} 完成任务")
# 创建一个线程列表
threads = []
# 启动10个线程
for i in range(10):
thread = threading.Thread(target=worker, args=(i,))
threads.append(thread)
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
print("所有线程已完成")
2024-07-260
背景:想要在两个不同的服务器之间进行数据传输,尝试了nc和scp命令,都没反应,经过不断地摸索,发现通过python创建一个服务,从而实现通过wget 命令实现文件的传输
- 首先一定要使用python2相关的版本
- python服务的开启执行命令为
python -m SimpleHTTPServer {端口} - 使用case
- 在要传输的文件在/home/map/test目录下
- 则在此目录下输入上述命令,开启一个服务, 设置端口为一个未使用的端口8877

- 在目前机器下进行文件拉取
shwget 目标ip:8877/待拉取的文件.txt

曹子昂
功不唐捐,日拱一卒